Image nets are often refer to neural networks that takes in one image (usually RGB image) and are supposed to output the class of the object shown in the image. There are a lot of famous and published image nets. They were pre-trained on slightly different datasets, developed by different teams in different time, but all widely used in not only object classification, but also many other applications. This article will go through several famous image neural networks (AlexNet, VGG, ResNet, InceptionNet, EfficientNet). And talk about their development background, the tricks introduced and differences between them. To talk about all of them, it all starts with a dataset and a competition.
ImageNet and Image Nets
I will start by talking about the main teaching staff of CS231N of Stanford, also director of the Artificial Intelligence Lab at Stanford, Li Fei-Fei, who, back in 2003, realized the limitations to achieve the concept: “a better algorithm would make better decisions, regardless of the data[1]”. That’s the lack of a large public dataset that enables ML algorithm teams to test their models on. With this in mind, she started to build a dataset.
“We decided we wanted to do something that was completely historically unprecedented. We’re going to map out the entire world of objects.”
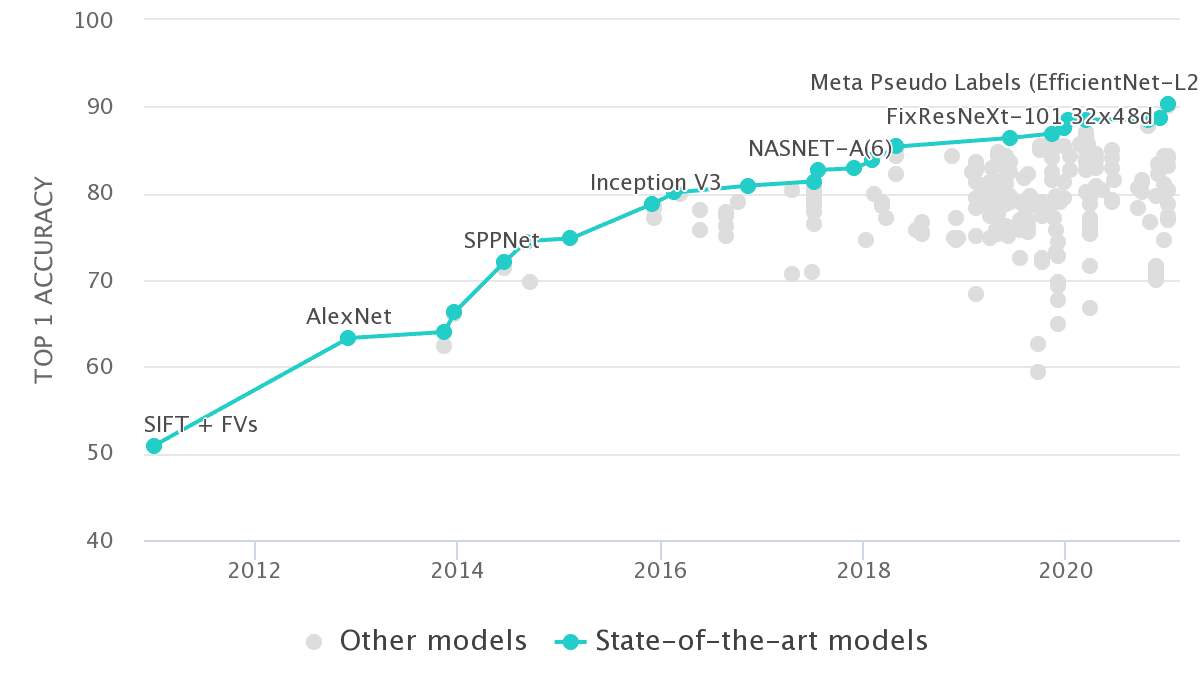
And in 2009, Li and her team published the first ImageNet paper to CVPR. That was a time when people are still very skeptical of how large scale datasets would help in building better algorithms. But later this data becomes much more famous and popular, partially because of the success and stunning results of the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), which is a competition/challenge using the ImageNet data to test the models’ classification accuracy.
And this challenge is also the reason why we have mention ImageNet as an intro chapter: the popular image net models that I wanna about to talk about pretty much were the candidates of ILSVRC initially (e.g. 2012: AlexNet; 2014: VGG; 2014: InceptionNet (v1); 2015: ResNet; 2019: EfficientNet).
AlexNet
AlexNet achieved a top-5 error of 15.3% in the 2012 ILSVRC, more than 10.8 percentage points lower than that of the runner up. The original paper’s primary result was that the depth of the model was essential for its high performance (though today, we may not think it’s that deep anymore), which was computationally expensive, but made feasible due to the utilization of GPUs [3]. The architecture of the model looks like the following:
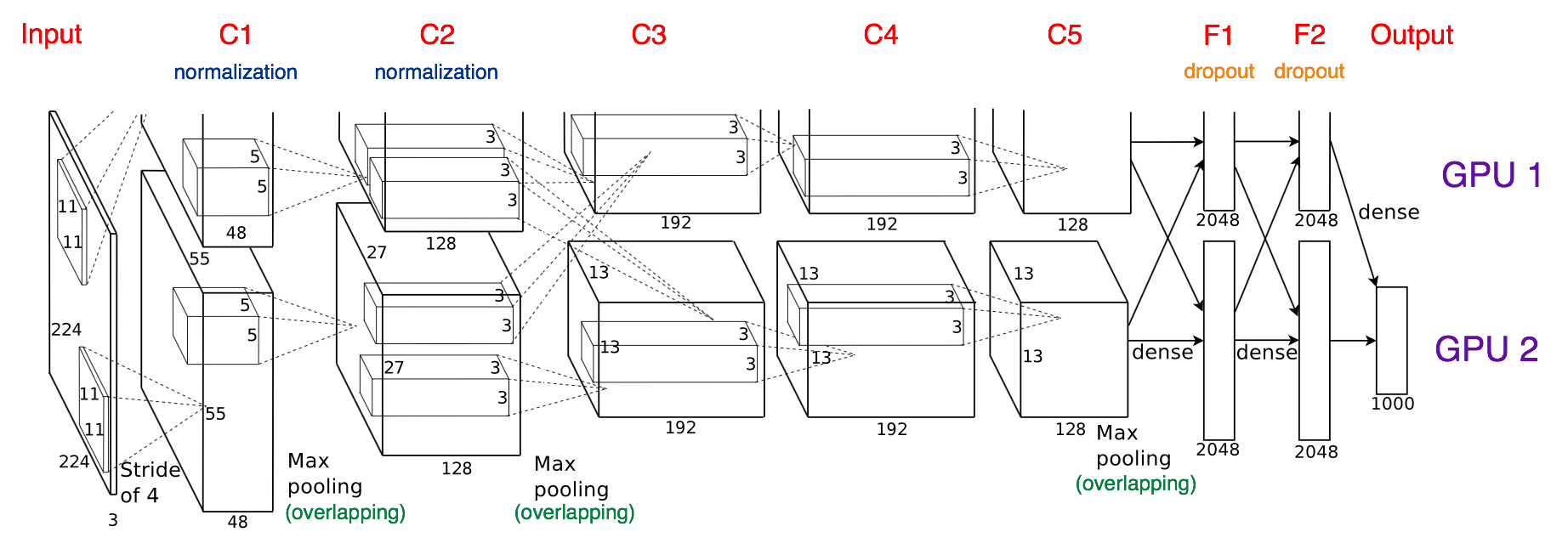
The features of this network is that:
- Firstly, it introduced ReLU into the model as activation function for non-linearity.
- And secondly, as mentioned above, trained in multiple GPUs, which was not that convenient as today, when we have more comprehensive deep learning packages that can do a lot of things under the hood.
- Finally, overlapping pooling is another trick that they used during training. Overlapping pooling offers about 0.5% of error rate drop, and makes the model harder to overfit. But the reasons of these benefits is not easy to summarize, refer to this article for detail.
To reduce overfitting, they took 2 main methods:
Data augmentation: including extracting random 224 $\times$ 224 patches horizontal reflections, and altering RGB intensities.
Dropout: it was a “recently-introduced technique” at the time, and they set the dropout rate to be 0.5. Dropout layers were added in the first two FC layers in the model.
VGG
VGG was the 1st runner-up of the 2014 ILSVRC, and was invented by Simonyan and Zisserman from Visual Geometry Group (VGG) at University of Oxford. The data trained and tested was much larger: 1.3 million training images from 1000 classes; 100,000 test images. The model finally achieved 92.7% test accuracy and has successful applications in many real world problems. The architecture looks like this:

VGGNet consists of 16 convolutional layers and is very appealing because of its very uniform architecture. Similar to AlexNet, only 3x3 convolutions, but lots of filters. Trained on 4 GPUs for 2–3 weeks. It is currently the most preferred choice in the community for extracting features from images. The weight configuration of the VGGNet is publicly available and has been used in many other applications and challenges as a baseline feature extractor. However, VGGNet consists of 138 million parameters, which can be a bit challenging to handle.
It’s noted in their [paper](https://arxiv.org/pdf/1409.1556.pdf(2014.pdf) that they used “multi-scale training” training + testing, which means for generalizability and practical applicability, they would scaled the images into various sizes and crop them to expected size.
It’s simply convolutional layers and max pooling layers, with three fully connected layers at the end. But the fact that it actually improved the performance and accuracy of the classification task hinders that by scaling the model: increasing the parameter size (width and depth), would give the model more power to solve complex problems, without any algorithmic innovations. This “theory”, though haven’t been fully understood even today, more or less triggers the invention of EfficientNet and one of this year’s highlight – GPT-3.
ResNet
At last, at the ILSVRC 2015, the so-called Residual Neural Network (ResNet) by Kaiming He et al introduced a novel architecture with “skip connections” and features heavy batch normalization. Such skip connections are also known as gated units or gated recurrent units and have a strong similarity to recent successful elements applied in RNNs. Thanks to this technique they were able to train a NN with 152 layers while still having lower complexity than VGGNet. It achieves a top-5 error rate of 3.57% which beats human-level performance on this dataset.
ResNet introduced a new structure – make direct data connection between every two convolutional layers, which can be interpreted as let the model to learn the function of $f(x) = x$ (identity function) more easily, or only learning the residual, or make the model to adjust its layer number according to the complexity of the problem, make deep model more trainable etc.
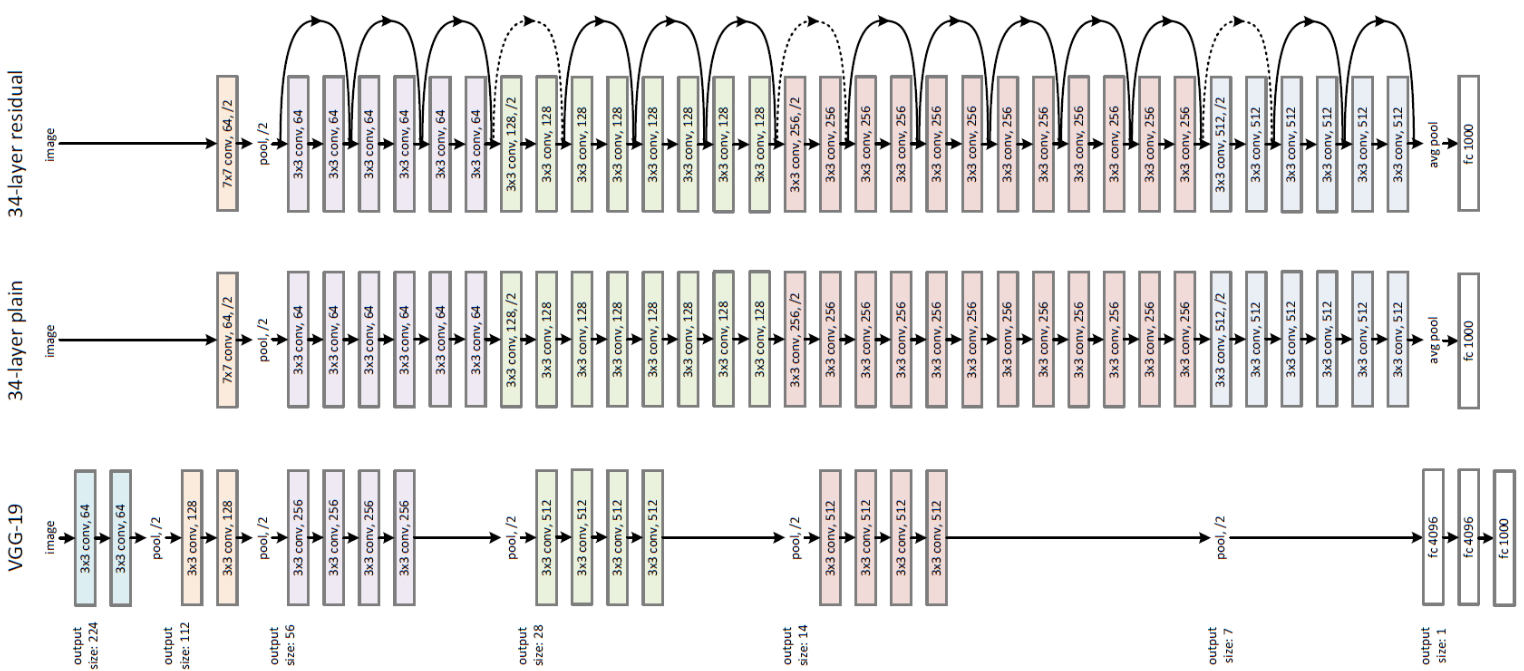
In ResNet paper, they discovered that the depth of the network is a very important factor for better performance. So they designed a deeper network than VGG. However, they controlled the dimensions of the convolutional kernels so that the total parameter size is smaller than VGG (ResNet18: ~11 million vs. VGG16: ~128 million).
Batchnorm is vastly applied in ResNet, because obviously, the Residuals should not be in the same scale as the result, while the result from each layer should be in the similar scale. The residual block (the substructure of every two conv layers) is vividly shown below:

– Dive into Deep Learning
InceptionNet
Inception net is actually a series of networks, from V1 to V4. Starting from 2014 and v4 was introduced in 2018.
InceptionNet v1 (GoogLeNet)
The problem is similar to VGG’s multi-scale training: pictures in real life can vary and the object of interest is different in sizes. Instead of changing the training images, inception net changes the kernel sizes. This is done by using multiple kernel sizes for each step, which is called inception module.
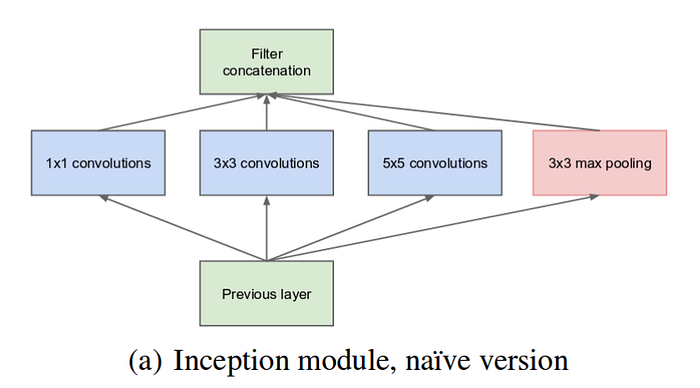
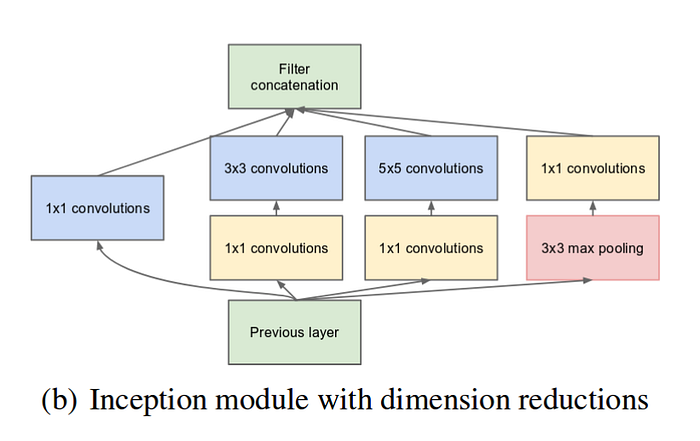
Note that these modules arWe chosen for some reason. The team wanted to make inception net to be very deep so that it handles more complex problems. That requires convolutional layers to be computationally cheap in a sense. So size of 1, 3, 5 were chosen. Plus, the simple kernels and max pooling layer, also adds some sort of convenience for modeling the identity function, which was recommended by ResNet.
InceptionNet v2 + v3
These two versions are introduced in the same papar, they are also focused on reduce the computational complexity even more. They factorized an $n \times n$ convolutional layer into a combination of $1 \times n$ and $n \times 1$ layers. So the new inception module looks like the following:

InceptionNet v4
Version 4 followed a new trend: making the module to be more uniformed – the reduced the implementation of the network; cut some of the unnecessarily complicated modules; make the whole module to be more customizable (think of LEGO).
EfficientNet
An brief introduction by themselves for the EffecientNet paper:
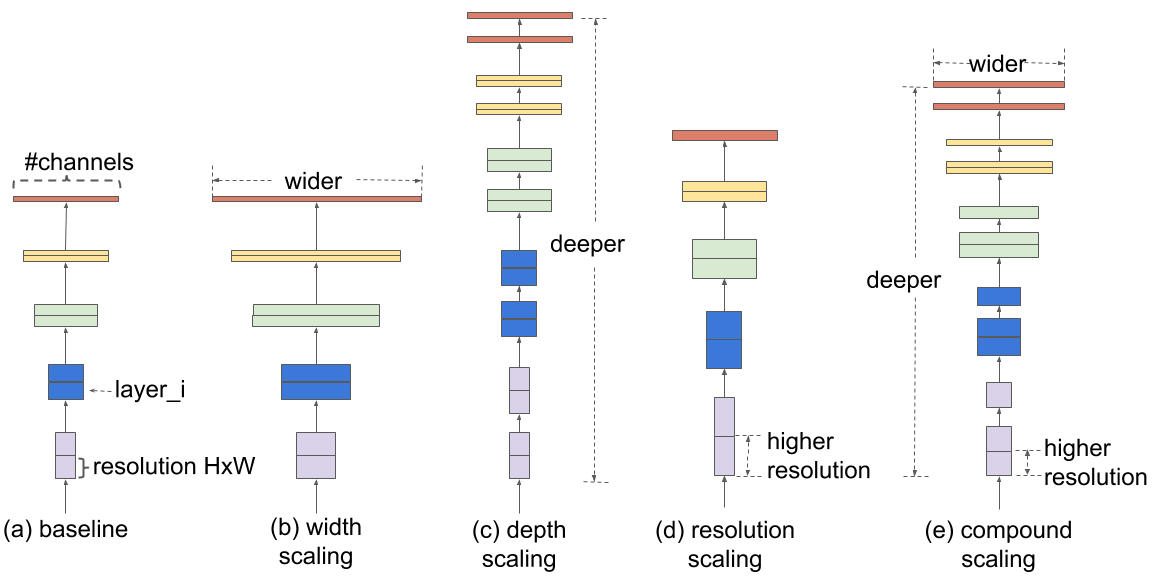
In our ICML 2019 paper, “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks”, we propose a novel model scaling method that uses a simple yet highly effective compound coefficient to scale up CNNs in a more structured manner. Unlike conventional approaches that arbitrarily scale network dimensions, such as width, depth and resolution, our method uniformly scales each dimension with a fixed set of scaling coefficients. Powered by this novel scaling method and recent progress on AutoML, we have developed a family of models, called EfficientNets, which superpass state-of-the-art accuracy with up to 10x better efficiency (smaller and faster).
Efficient net started with a very good baseline model (EfficientNet B0), which uses a small amount of parameters to achieve an OK performance. Simply scaling that model gives them better and better results. They are taking scaling in two dimensions (width and depth) and through experimentations, they discovered the best efficiency of scaling is obtained by simultaneously increase both depth and width, which they called compound scaling.
Other References
[2] Best deep CNN architectures and their principles: from AlexNet to EfficientNet | Nikolas Adaloglou | AI SUMMER
[4] Key Deep Learning Architectures: AlexNet | Max Pechyonkin | Median
[5] ImageNet Classification with Deep Convolutional Neural Networks